

چگونگی عملکرد تنسورفلولایت برای موبایل

در این مقاله میخواهیم راجع به چگونگی عملکرد تنسورفلولایت برای موبایل صحبت کنیم.
اگر تا کنون برای یک بار هم یک مدل هوش مصنوعی را اجرا کرده باشید، متوجه شده اید که معمولا این مدلها برای اجرای بهینه، نیاز به ریسورسهای (CPU, GPU, …)بالایی دارند و بدیهی ست که با این تفاسیر، برای پروسس های مدلهای پیچیده ی هوش مصنوعی، مانند مدلهای تشخیص اشیاء، خواندن متن تصاویر و ویدیوها، تشخیص گفتار و … نیاز به سرورهای خاص با ریسورسهای بالا میباشد و اگر سؤال شود که آیا همین مدلهای هوش مصنوعی با همین پیچیدگی، آیا روی موبایل ها یا دستگاههای پردازش محدود (resource- constrained یا Edge Devices) به راحتی قابل اجرا میباشند یا نه؟ قطعاً جواب منطقی و درست به این سؤال منفی خواهد بود. همین موضوع مانع اصلی برای استفاده بیش را پیش از این مدلها بر روی دستگاههای پردازش-محدود(Edge Devices) مانند موبایل های هوشمند، سامانه های نهفته (Embedded Systems) مثل رزبری پای و … و در نتیجه تعمیم یافتن این تکنولوژی روی میلیاردها دستگاه الکترونیکی شده است.
یکی از روشهای معمول برای استفاده از چنین مدلهای سنگینی بر روی دستگاههای پردازش محدود(موبایل)، کاستن از پیچیدگی این مدلهاست که مستقیماً بر روی دقت مدل تأثیر منفی گذاشته و از بازدهی آن می کاهد. و در صورتی که فاکتور دقت برای ما مهم باشد و اصرار به حفظ دقت مدل خود هنگام استفاده بر روی دستگاههای پردازش محدود داشته باشیم، معماری شبکه ی مرتبط با اپلیکیشن خود را باید به صورت سرور پایه (Server Based) طراحی کنیم و مدل هوش مصنوعی خود را روی یک سرور دیگر در بیرون از دستگاه اجرا کنیم و از طریق اینترنت یا شبکه ی کامپیوتری دیگر، دادهها را طریق اپلیکیشن دریافت و به سمت سرور ارسال کنیم و پس از پردازش روی سرور خارجی، نتیجه ی پردازش مجدداً از طریق شبکه اینترنت یا … به اپ بازگردانده می شود و اپلیکیشن آن را برای یورز نمایش می دهد. اما این روش، روشی بهینه و کارآمد نخواهد بود. چرا؟
***چگونگی عملکرد تنسورفلولایت برای موبایل***
به چند علت، که سه علت مهم آن به شرح زیر است:
۱. زمان رفت و آمد دیتا و تایم پردازش روی سرور به زمان عملکرد اپلیکیشن اضافه میشود و سرعت پاسخگویی اپ را کاملاً کند می کند. و در صورت کند بودن سرعت نت(که مشکلی رایج است) عملاً اپلیکیشن از کار خواهد افتاد.
۲. با توجه به خبرهای روزانه ی فاش شدن اطلاعات از شرکت های بزرگ و سو استفاده هایی که از این اطلاعات می شود، کاربرهای فضای مجازی نسبت به حریم و اطلاعات شخصی خود حساستر میشوند و دولت ها نیز مطابق با خواسته ی شهروندانشان، قوانین سخت تری را برای نشر اطلاعات خصوصی شهروندان در فضای مجازی تصویب می کنند. به همین دلیل پیشبینی میشود که اقبال شهروندان نسبت به اپلیکیشن های سرور پایه کم و کمتر شود و همچنین استفاده از این اپلیکیشن ها بواسطه ی قوانین شهروندی محدود و محدود تر خواهد شد. به طور مثال، اپلیکیشنی که نقش چشم افراد نابینا را بازی میکند. روبروی آنها را میبیند، موانع را به آنها متذکر میشود و طبق خواسته ی فرد نابینا صحنه ی اطراف وی را توصیف میکند. قاعدتاً این اپلیکیشن برای چنین کاری، نیازمند دریافت تصویر یا ویدیو از دوربین موبایل و آنالیز این تصاویر توسط مدل هوش مصنوعی خود است. اما سؤال اینجاست که اگر این اپلیکیشن سرور پایه باشد و تصاویر خصوصی ترین اوقات و ملاقات های کاربر را برای آنالیز به سروری خارج از موبایل وی ارسال کند، کاربر نابینا، نسبت به این عمل چه حسی خواهد داشت؟ قطعاً حس خوبی را تجربه نخواهد کرد و تمایلش برای استفاده از آن به شدت کم خواهد بود. اما اگر تمام این پردازشها، بر روی خود موبایل انجام شود چطور؟ قطعاً احساس امنیت بیشتری را به کاربر خواهد داد. اما مشکل فنی مطرح شده را هم فراموش نکنیم که آیا میتوان چنین مدل سنگینی را روی موبایل که یک دستگاه پردازش محدود هست، اجرا کرد؟
۳. هزینه ی تهیه ی سرور و حفظ و ارتقای آن چقدر است؟ اصطلاحاً ماهی چقدر آب می خورد؟ حواستان باشد منظور از سرور، یک سرور GPU با توانایی پردازش درخواست هزاران کاربر بصورت همزمان است. قطعاً با یک محاسبه ی سرانگشتی، به این نتیجه خواهید رسید که بهتر است کاری بکنید که مدل هوش مصنوعی ای طراحی کنید که هم دقیق باشد و هم آنقدر چابک، سبک و سریع باشد که بر روی موبایل هم قابل اجرا باشد تا دیگر نیازی به تهیه ی سرور و هزینههای مرتبط با آن نباشد. اما آیا میتوان چنین مدلی طراحی کرد؟ اگر جواب این سؤال مثبت است، چگونه میشود چنین مدل هوش مصنوعی ای را تولید کرد؟

جواب این سؤالات را میتوان در سرمایهگذاری عظیم شرکت های بزرگ فن آوری در زمینه ی پردازش بر روی دستگاههای پردازش محدود (On-Device Processing) و تولید پلتفرم هایی همچون تنسورفلولایت جستجو کرد. اگر در چندسال اخیر جهت و سمت و سوی تحقیقات شرکت های بزرگ مانند گوگل، اپل، مایکروسافت، متا، هواوی و شیایومی را دنبال کرده باشید، خواهید دید که یکی از مباحث مهمی که آنها دنبال کردهاند تعمیم هوش مصنوعی در بین عام مردم، به کار گیری بیش از پیش آن بر روی محصولات خود و اجرای مدلهای هوش مصنوعی بر روی دستگاههای پردازش محدود است. به همین علت مایکروسافت(Edge ML)، اپل(Create ML)، متا(Pytorch Lite)، هواوی(Hi AI)، شیایومی(MACE) ابزار و پلتفرم های خود را معرفی کرده اند. اما قویترین ابزار در این زمینه را گوگل با نام تنسورفلولایت (Tensorflow Lite) معرفی کرده است که موضوع مقاله ی حاضر است.
تنسورفلولایت مجموعهای از ابزارهایی ست که مسیر استفاده از مدلهای ماشین لرنینگ یا هوش مصنوعی بر روی اصطلاحاً دستگاههای پردازش محدود مثل موبایلها، سیستمهای نهفته(Embedded Systems) مانند رزبری پای، میکروکنترلرها و … را هموار می کند.
یکی از قدرتمندترین، مفیدترین و شاید حیرت انگیزترین مزیتهای تنسورفلولایت، معرفی تکنیک های بهینه سازی مدل (Model Optimization) خاصی است که با استفاده از آنها، توسعه دهندگان این امکان را می یابند که مستقل از شرکت تولید کننده ی شتاب دهنده (accelerator; CPU, GPU) ، سیستم عامل یا حتی قدرت پردازش سیستمها، از طریق درگاه های مختلف(Delegate) مانند (GPU, CPU, NNAPI, CORE ML, …)، مدل هوش مصنوعی خود را با تأخیر (Latency) حداقلی و دقت (Accuracy) حداکثری روی دستگاههای پردازش محدود اجرا کنند. (گرچه برای دریافت حداکثر بازدهی از مدل، استفاده از سخت افزارهای پیشنهادی گوگل پیشنهاد می شود.) و این انقلابی در سطح هوشمندی دستگاههای پردازش محدود است. اگرچه هنوز این فناوری به بلوغ نرسیده است و راه زیادی تا رسیدن به پختگی مورد نظر دارد اما با توجه به سرمایهگذاری انجام شده، ترند شدن این تکنولوژی در آیندهای نزدیک بعید نیست.
حالا سؤال اینجاست که تنسورفلولایت چگونه یک مدل هوش مصنوعی را برای اجرا روی دستگاه پردازش محدود آماده می کند؟(چگونگی عملکرد تنسورفلولایت برای موبایل؟)
مراحل آماده سازی مدل را میتوانید بطور خلاصه در شکل زیر ببینید:
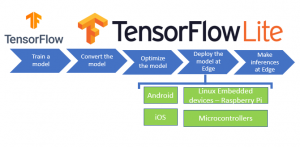
مرحله اول: آموزش مدل
آموزش مدل(Train Model) موضوع جدیدی نیست. همان آموزش دادن مدل طراحی شده ی یادگیری ماشین است که توسط توسعه دهندگان پیش از این هم انجام میشده است.
مرحله دوم: تبدیل مدل
تبدیل(Convert) به نوعی آماده سازی مدل برای مرحله ی بهینه سازی (Optimization) است. خروجی این مرحله، مدلی با فرمت TFLITE است که فرمت مربوط به پلتفرم تنسورفلولایت است. نمونه ای از کد تبدیل (Convert) را در زیر میتوانید مشاهده کنید:
الف. نمونهای از کد کانورت یا تبدیل مدل ذخیره شده با فرمت h5، با پایتون:
import tensorflow as tf
Convert the model#
converter = tf.lite.TFLiteConverter.from_saved_model(saved_model_dir)
path to the SavedModel directory#
()tflite_model = converter.convert
. Save the model#
: with open(‘model.tflite’, ‘wb’) as f
f.write(tflite_model)
***چگونگی عملکرد تنسورفلولایت برای موبایل***
ب. نمونهای از کد تبدیل مدل کراس مدل (Keras Model) در پایتون:
import tensorflow as tf
Create a model using high-level tf.keras.* APIs#
])model = tf.keras.models.Sequential
, tf.keras.layers.Dense(units=1, input_shape=[1])
, tf.keras.layers.Dense(units=16, activation=’relu’)
tf.keras.layers.Dense(units=1)
([
model.compile(optimizer=’sgd’, loss=’mean_squared_error’) # compile the model
model.fit(x=[-1, 0, 1], y=[-3, -1, 1], epochs=5) # train the model
(to generate a SavedModel) tf.saved_model.save(model, “saved_model_keras_dir”)#
Convert the model#
converter = tf.lite.TFLiteConverter.from_keras_model(model)
tflite_model = converter.convert()
Save the model#
:with open(‘model.tflite’, ‘wb’) as f
f.write(tflite_model)
لازم به ذکر است که ساختار کد، با توجه به مدل و شرایط آن تغییر می کند. و این نمونه صرفاً برای آشنایی اولیه با ساختار آن آمده است.
مرحله سوم: بهینه سازی مدل
بهینه سازی مدل (Model Optimization) مهمترین و پیچیده ترین قسمت برای آماده سازی مدل جهت استفاده روی دستگاههای پردازش محدود است.درواقع این قسمت چگونگی عملکرد تنسورفلولایت برای موبایل را مشخص میکند.
در این مرحله از ابزارهایی که گوگل به جهت بهینه سازی (Optimization) معرفی کرده است برای افزایش سرعت اجرای مدل و جلوگیری از کاهش چشمگیر دقت مدل استفاده میکنیم و این مورد باعث میشود که مدلهای سنگین یادگیری ماشین با دقت و سرعت خوبی بر روی دستگاههای مورد نظر اجرا شوند.
علاوه بر این مورد، ابزارهای بهینه سازی مدل، به ما این اجازه را میدهند که مدل هوش مصنوعی خود را با توجه به شتابدهنده ی مدنظرمان بهینه سازی کنیم. به عنوان مثال من میخواهم از GPU ی موبایل برای اجرای مدل استفاده کنم، یا از CPU استفاده کنم یا اینکه قصد دارم با توجه به شرایط، خود مدل انتخاب کند که روی کدام شتابدهنده (ACCELERATOR)مدل ما اجرا شود که در این صورت NNAPI را انتخاب می کنم. برای هر کدام از این شرایط تنسورفلولایت راه حل دارد. که در چند جمله ی دیگر راجع به این راه حلها صحبت خواهیم کرد.
تکنیک هایی که در بهینه سازی استفاده میکنیم را میتوان به سه قسمت تقسیم کرد:
کوانتیزیشن(Quantization)، پرانینگ(Pruning) و خوشه بندی (Clustering)
مهمترین و کارامدترین تکنیک بهینه سازی، کوانتیزیشن است. به همین خاطر در ادامه ی این مقاله به این مورد خواهم پرداخت.
کوانتیزیشن(Quantization):
در این روش، از حذف بعضی وزن های مدل و تغییر نوع دادههای آن، برای کاهش سایز و افزایش سرعت مدل استفاده می شود. گرچه سعی میشود که با اعمال این روش، دقت مدل کمترین کاهش را داشته باشد.
با توجه به الگوریتمی که کوانتیزیشن برای بهینه سازی بر روی مدل اعمال می کند، این روش به ۴ دسته تقسیم می شوند:
– Post-training float 16 quantization
– Post-training dynamic range quantization
– Post-training integer quantization
– Quantization-aware quantization
جالب است بدانید که هر کدام از روشهای کوانتیزیشن فوق، معمولاً مختص به یک یا دو شتابدهنده ی خاص می باشد. همانطور که پیش از این گفته شد، میتوانیم مدل خود را با توجه به شتابدهنده ای که مدلمان را میخواهد اجرا کند با انتخاب یکی از روشهای فوق اپتیمایز کنیم.
در شکل زیر میتوانیم ببینیم که هر کدام از روشهای کوانتیزیشن چه تأثیری بر روی دقت و حجم مدل ما دارند و چه سخت افزارهایی را پشتیبانی می کنند.
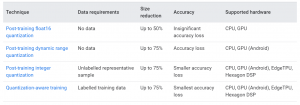
همانطور که مشاهده میکنید در جدول فوق، روش Post-training float 16 quantization سایز مدل بیش از ۵۰ درصد کاهش داشته است در حالی که کاهش دقت ناچیزی را تجربه میکند. و گوگل در این گزارش تأکید میکند که این نوع کوانتیزیشن مخصوص اجرای مدل بر روی CPU و GPU ست و در روش دیگری به نام integer بیش از ۷۵ درصد کاهش حجم داریم در حالی که کاهش کمی را در دقت مشاهده میکنیم و این روش نیز مختص برای اجرا روی موبایلهایی ست که دارای یکی از سخت افزارهای CPU, GPU, TPU, HEXAGON می باشند.
همچنین به طور دقیقتر، در جدول زیر میتوانیم تأثیر هر کدام از روشهای کوانتیزیشن را بر پارامترهای تاخیر(Latency), دقت (Accuracy) و سایز مدل(Model) را بر روی مدلهای نام آشنای MobileNet-V1 , MobileNet-V2, Inception, Resnet ببینیم.

همانطور که مشاهده میکنیم در طی فرایند کوانتیزیشن میزان سایز به شدت کاهش یافته است در حالی که دقت مدل تقریباً در همان حد مدل واقعی باقیمانده است. و این معجزه ی تنسورفلولایت می باشد. به عنوان مثال تست بر روی مدل MobileNet-V1 با کوانتیزیشن post-train دقت تنها ۵ درصد کم شده است در حالی که سایز مدل نزدیک به ۷۵ درصد و تأخیر آن (inference time) از ۶۴ میلی ثانیه به ۱۶ میلی ثانیه کاهش داشته است.
بعد از کوانتیزیشن، مدل آماده ی استفاده بر روی دستگاه های پردازش محدود با سرعت بالا و تأخیر کم می باشد.
در نتیجه میتوان گفت که تنسورفلولایت مجموعه ابزاری مطمین برای بهینه سازی مدلهای سنگین به منظور اجرا بر روی دستگاههای پردازش محدود است و از این مجموعه ابزار میتوان برای انقلابی در بالاتر بردن سطح هوشمندی دستگاههای همراه و همچنین اجرای اپلیکیشن های هوشمند خود استفاده کرد.
نویسنده : محمود علیپور
مطالب زیر را حتما مطالعه کنید

خلاصه وضعیت هوش مصنوعی در سال ۲۰۲۳ در ۱۰ نمودار

هوش مصنوعی مولد و کاربرد های آن

مایکروسافت در برابر گوگل: رقابت چت بات ها در جستجوی اینترنتی

شبکه های عصبی چیست؟ تاریخچه، انواع و آینده آن

هوش مصنوعی چیست؟

دیدگاهتان را بنویسید