

شبکه های عصبی چیست؟ تاریخچه، انواع و آینده آن
شبکه های عصبی تکنیکی محبوب در یادگیری ماشین هستند که مکانیزم یادگیری در موجودات زنده را شبیهسازی میکنند. در این مقاله به طور جامع و کلی به انواع شبکه های عصبی مانند پرسپترون تک لایه و چند لایه و شبکه های عصبی عمیق مانند شبکه عصبی کانولوشن، شبکه عصبی بازگشتی و ترنسفورمرها میپردازیم.
پرسپترون تک لایه
ساده ترین نوع شبکه عصبی پرسپترون است که توسط فرانک روزنبلت (Rosenblatt) در سال ۱۹۵۸ ارائه شد. این شبکه عصبی شامل یک لایه ورودی و یک گره خروجی است که در آن لایه ورودی ویژگی ها را به گره خروجی منتقل می کند. لبههای لایه ورودی به خروجی حاوی وزن های W1 تا Wd است که با آن ویژگی ها در هم ضرب و سپس در گره خروجی جمع میشوند. در نهایت، تابع علامت (Sign Function) به منظور تبدیل مقدار تجمیع شده به کلاسی برای طبقهبندی اعمال میشود. تابع علامت نقش یک تابع فعال سازی را ایفا میکند و توجه داشته باشید که لایه ورودی در شمارش تعداد لایههای شبکه عصبی لحاظ نمیشود و از آنجایی که پرسپترون دارای یک لایه محاسباتی است، یک شبکه تک لایه در نظر گرفته می شود.
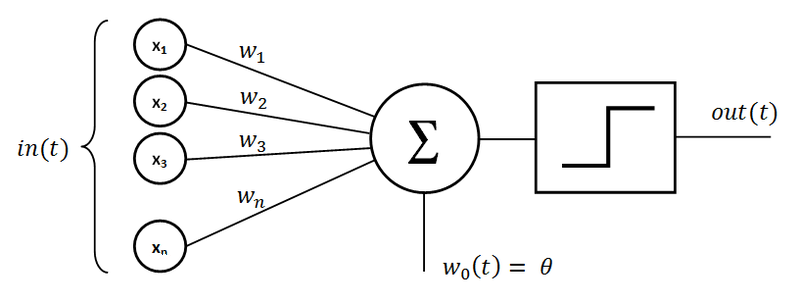
الگوریتم پرسپترون تک لایه زمانی که داده ها به صورت خطی قابل تفکیک هستند، به خوبی عمل می کند اما با داده های غیرخطی عملکرد خوبی ندارد. همین مسئله محدودیت ذاتی در مدلسازی مسئله در پرسپترون را نشان میدهد که استفاده از معماریهای عصبی پیچیدهتر را ضروری میکند.
شبکههای عصبی چند لایه
شبکه های عصبی چند لایه (Multi-Layer Neural Network) دارای بیش از یک لایه محاسباتیاند. لایههای محاسباتی که بین لایه ورودی و خروجی است، لایه های پنهان نامیده می شوند زیرا محاسباتی که انجام میشود برای کاربر قابل مشاهده نیست. به معماری خاص شبکه های عصبی چند لایه، شبکههای عصبی پیشخور (Feed-Forward Neural Network) هم گفته میشود، زیرا لایه ها به طور متوالی و به سمت جلو یکدیگر را تغذیه میکنند از لایه ورودی تا لایه خروجی.
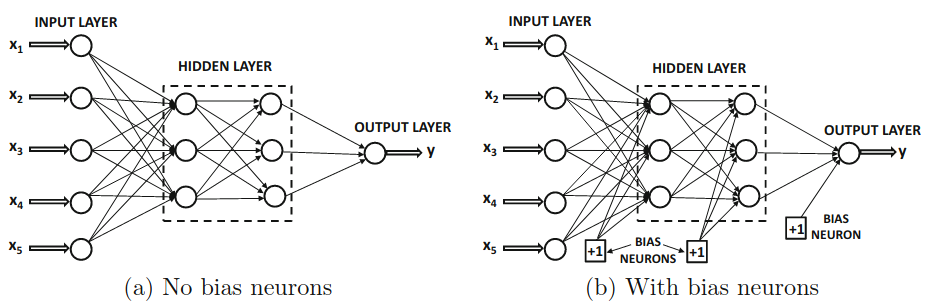
شبکه های عصبی عمیق
همانطور که در مقاله هوش مصنوعی چیست اشاره شد، به شبکه های عصبی با سه لایه یا بیشتر شبکه عصبی عمیق گفته میشود.
شبکه های عصبی کانولوشن
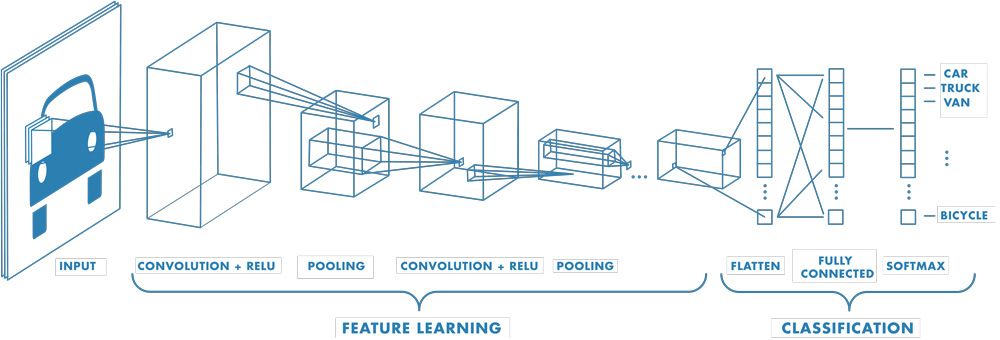
شبکه های عصبی کانولوشن (Convolutional Neural Network) شبکههایی الهام گرفته شده از طبیعت هستند که در بینایی کامپیوتر (Computer Vision) برای طبقه بندی تصاویر و تشخیص اشیا استفاده می شود. انگیزه اصلی برای طراحی شبکه های عصبی کانولوشن از درک هوبل و ویزل (Hubel and Wiesel) از عملکرد قشر بینایی گربه به دست آمد است که در آن به نظر میرسد بخشهای خاصی از میدان بینایی گربه، نورونهای خاصی را فعال می کند.
شبکه های عصبی کانولوشن دارای سه نوع لایه اصلی به شرح زیر است:
با هر لایه، شبکه عصبی کانولوشن پیچیدگی خود را افزایش می دهد و بخش های بیشتری از تصویر را شناسایی می کند. لایه های قبلی بر روی ویژگی های ساده مانند رنگ ها و لبه ها متمرکزاند و همانطور که داده های تصویر در لایه های این شبکه به پیش میروند، این شبکه عصبی شروع به تشخیص عناصر یا اشکال بزرگتر می کند تا اینکه در نهایت شی مورد نظر را شناسایی می کند.
الف) لایه کانولوشن: لایه کانولوشن اولین لایه از یک شبکه عصبی کانولوشنال است. لایه کانولوشن بلوک اصلی این شبکه عصبی است و لایهای است که اکثر محاسبات در آن انجام می شود. این لایه به چند جزء احتیاج دارد که عبارتاند از دادههای ورودی، فیلتر و نگاشت ویژگی (Feature map). فرض کنید ورودی یک تصویر رنگی است که از ماتریسی از پیکسل ها به صورت سه بعدی تشکیل شده است. این به این معنی است که عکس ورودی دارای سه بعد ارتفاع، عرض و عمق است. البته یک جزء تشخیص ویژگی (Feature Detector) وجود دارد که به عنوان هسته یا فیلتر نیز شناخته می شود، که دربخشهایی از تصویر حرکت می کند و بررسی می کند که آیا این ویژگی وجود دارد یا خیر. این فرآیند به عنوان یک فرآیند کانولوشن شناخته میشود
ب) لایه Pooling:
لایههای Pooling، کاهش ابعاد را انجام می دهند و تعداد پارامترها را در ورودی کاهش می دهد. با آنکه اطلاعات زیادی در لایه Pooling از بین میرود اما مزایای زیادی برای شبکه عصبی کانولوشن دارد برای مثال این لایه به کاهش پیچیدگی، بهبود کارایی و کمکردن خطر ریسک بیشبرازش (Overfitting) کمک می کند.
پ) لایه تمام متصل (Fully-Connected)
در لایه تمام متصل، هر گره (Node) در لایه خروجی مستقیماً به یک گره در لایه قبلی متصل می شود. این لایه وظیفه طبقهبندی بر اساس ویژگی های استخراج شده از لایههای قبلی را بر عهده دارد. در حالی که لایههای کانولوشن و Pooling معمولا از توابع ReLu استفاده کنند، لایههای تمام متصل معمولاً از یک تابع فعالسازی به نام softmax برای طبقهبندی استفاده میکنند و خروجی این تابع احتمالی بین 0 تا 1 است.
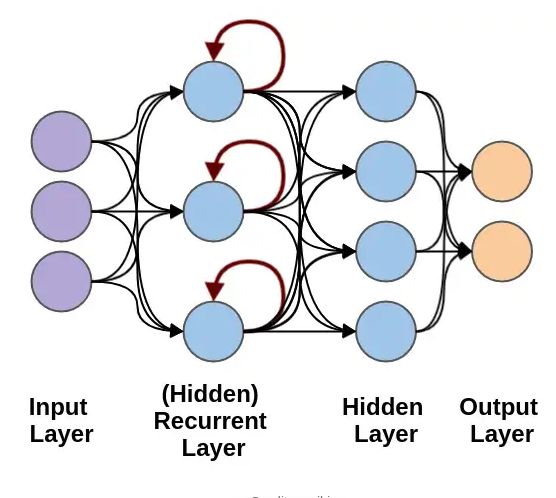
شبکه های عصبی بازگشتی
شبکه های عصبی بازگشتی (Recurrent Neural Network) نوعی از شبکه های عصبی است که از داده های متوالی (Sequential) یا داده های سری زمانی استفاده میکند. این الگوریتم معمولاً برای مسائلی مانند ترجمه، پردازش زبان طبیعی ، تشخیص گفتار و شرح تصاویر مناسب است چراکه در این مسائل دادهها متوالی هستند. این نوع از شبکههای عصبی در برنامه های محبوبی مانند اپل سیری (Siri)، جستجوی صوتی و مترجم گوگل استفاده میشوند و مانند شبکه های عصبی چندلایه و شبکه های عصبی کانولوشن، به طور مکرر از دادههای آموزشی برای یادگیری استفاده می کنند.
شبکه عصبی بازگشتی را میتوان با «حافظهشان» متمایز شناخت زیرا این نوع شبکه عصبی اطلاعات را از ورودی های قبلی میگیرد تا بر ورودی و خروجی فعلی تأثیر بگذارد. شبکههای عصبی عمیق مانند شبکه عصبی کانولوشن فرض میکند که ورودیها و خروجیها مستقل از یکدیگر هستند اما خروجی شبکههای عصبی بازگشتی به عناصر قبلی در توالی بستگی دارد. از معروفترین شبکه های عصبی بازگشتی میتوان به شبکه عصبی LSTM و یا GRU اشاره کرد.
ترنسفورمر
ترنسفورمر (Transformer) یک نوع شبکه عصبی است که با ردیابی روابط در داده های متوالی، زمینه (Context) و در نتیجه معنا را یاد میگیرد. مدلهای شبکه عصبی ترنسفورمر از مجموعهای از تکنیکهای ریاضی به نام «توجه» استفاده میکنند تا ارتباطات نامحسوس را حتی در عنصرهایی از داده که از یکدیگر دور هستند اما همدیگر را تحت تأثیر قرارمی دهند و به هم وابستهاند را تشخیص میدهد.
برای مثال در جمله «او آب را از کتری داخل فنجانها ریخت تا آنها را پر کند» ما میدانیم که در اینجا واژه «آنها» اشاره به واژه «فنجانها» دارد.
حال این جمله را در نظر بگیرید: «او آب را از کتری داخل فنجانها ریخت تا آن را خالی کند»، که در اینجا واژه «آن» اشاره به کتری دارد.
«معنا نتیجه رابطه بین چیزهاست و مکانیزم توجه در [ترنسفورمرها] راهی عمومی برای یادگیری روابط است.» اشیش وسوان، پژوهشگر ارشد پیشین در تیم Google Brain
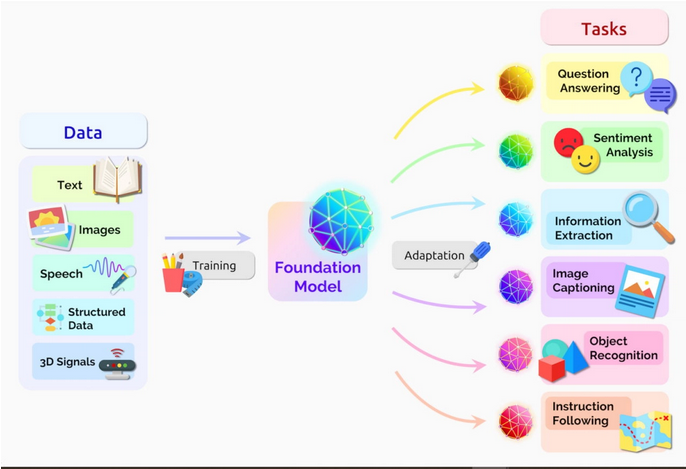
ترنسفورمرها یکی از جدیدترین و یکی از قویترین مدلهای شبکه عصبی است که تا به امروز اختراع شده است و این نوع از شبکه های عصبی موجی از پیشرفتها را در یادگیری ماشین به وجود آورده است که برخی آن را Transformer AI نامیدهاند.محققان دانشگاه استنفورد در مقاله ای در آگوست 2021 ترنسقورمرها را «مدل های پایه» نامیدند به این دلیل که این نوع از شبکه های عصبی یک تغییر در پارادایم (paradigm) هوش مصنوعی ایجاد می کند. اصولاً هر برنامه ای که از دادههای متنی متوالی (Sequential text)، عکس یا ویدیو استفاده می کند، کاندیدی برای مدل های ترنسفورمر است. به ترنسفرمرها مدلهای بنیادی (Foundational model) نیز گفته میشود.
بدون برچسب، با کارایی بیشتر
پیش از ترنسفورمرها، کاربران باید شبکه های عصبی را با دیتاستهای بزرگ و برچسب گذاری شده آموزش می دادند که تولید آنها پرهزینه و زمان بر بود. با یافتن الگوها بین عناصر به صورت ریاضی، ترنسفورمرها این نیاز را برطرف میکنند و استفاده از تریلیونها تصویر و پتابایت داده متنی را راحت و میسر میکند. همچنین، ریاضیاتی که ترنسفورمرها استفاده میکنند به پردازش موازی کمک میکند، بنابراین این مدلها میتوانند سریع اجرا شوند.
«ترنسفورمرها یادگیری خود نظارتی را ممکن کردند و سرعت [پیشرفت] در هوش مصنوعی به سرعت بالا رفت»، ینسن هوانگ، بنیانگذار و مدیر ارشد اجرایی شرکت انویدیا
ترنسفورمرها در بسیاری از موارد جایگزین شبکههای عصبی کانولوشن و شبکههای عصبی بازگشتی (CNN و RNN) میشوند که این دو شبکه عصبی، محبوبترین نوع مدلهای یادگیری عمیق در پنج سال پیش بودند.
مطالب زیر را حتما مطالعه کنید

خلاصه وضعیت هوش مصنوعی در سال ۲۰۲۳ در ۱۰ نمودار

هوش مصنوعی مولد و کاربرد های آن

مایکروسافت در برابر گوگل: رقابت چت بات ها در جستجوی اینترنتی

هوش مصنوعی چیست؟

آیا مدلهای هوش مصنوعی مانند GPT-3 میتوانند احساسات را تجربه کنند؟

دیدگاهتان را بنویسید